Always On, it is the feature that I liked the most. In the recent past, I have had so many setups. With the release of SQL Server 2016, automatic seeding was introduced. While setting up Always on for the customer, the most common error I have seen is Error 41169.
In this blog post today I will talk about how to fix Error 41169? And, I will also explain what is automatic seeding.
What is automatic seeding?
Basically, SEEDING is a process of propagation. Meaning, you are propagating the data and the changes to the other end, the server where you want your data to be available. This process is called seeding in Prior to the release of SQL Server 2016, the setup process was little different for Always On. You need to take the full backup followed by the log backup of the database you want to add to the Availability Group. Once you have the backup ready, you need to copy them to the Secondary Replica(s). Restore the full backup followed by the log backup with norecovery. And then you can add the database to the Availability Group. This process is the manual seeding process. With SQL Server 2016, the seeding process is changed and is now an automatic process. What that means is, it will create the database at the secondary replica. The only thing you need to make sure of is that the file layout should exactly match with the primary server.
Fixing Error 41169 on Always On
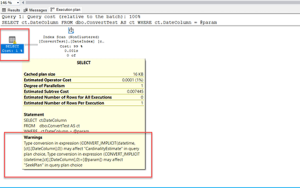
Now you know what automatic seeding is for Always On. We can discuss the Error 41169. This is a known issue that we have a KB article as well. There may be a chance that due to network or some other issues, automatic seeding may fail, and when it fails it will throw error 41169. Occasionally, you may also observe error 223 which means the database already exists. There is a new DMV dm_hadr_physical_seeding_stats that I have used to capture statistics and check the status. Let’s see how I have fixed Error 41169. I have already enabled the trace flag (TF) 9567. Enabling TF 9567 as a startup will help you seeding with compression, this is most helpful when you are dealing with the large databases. The database I was syncing was about 3 terabyte in size. And, there are about 3 replicas, 1 with Synchronous and 2 with the Asynchronous setup. What I have done is that I have changed the Seeding Mode from Automatic to Manual, apply the changes and then change back the seeding mode to Automatic and that did the trick.
SELECT local_database_name ,role_desc ,internal_state_desc ,transfer_rate_bytes_per_second ,transferred_size_bytes ,database_size_bytes ,start_time_utc ,end_time_utc ,estimate_time_complete_utc ,total_disk_io_wait_time_ms ,total_network_wait_time_ms ,is_compression_enabled FROM sys.dm_hadr_physical_seeding_stats
This was how the output looks like.

Changed the Automatic Seed from Automatic to Manual, apply changes, and change back automatic seeding to Automatic. Basically, stopped and started the Seeding.

Finally, the seeding process has started and seeding started to complete successfully.

Just so that it can help you, here is another script that I have written, it will give you the health status report for you availability group.
select n.group_name, n.replica_server_name, n.node_name, rs.role_desc, db_name(drs.database_id), drs.synchronization_state_desc, drs.synchronization_health_desc from sys.dm_hadr_availability_replica_cluster_nodes n join sys.dm_hadr_availability_replica_cluster_states cs on n.replica_server_name = cs.replica_server_name join sys.dm_hadr_availability_replica_states rs on rs.replica_id = cs.replica_id join sys.dm_hadr_database_replica_states drs on rs.replica_id=drs.replica_id
Do let me know how do you like this blog post? Have you encountered this error before? I will be interested to know how you’ve dealt with it. You may want to browse through HADR category of my blog for more tips like this.